As a foodie economist, one of the few things that makes my mouth water more than a good meal is good data about restaurants. The basest form of such data are the restaurant hygiene ratings I blogged about recently. For a foodie economist (though not an epidemiologist), more interesting data would include information about a restaurants cost and quality.
Zagat collects just such data. As you probably know, Zagat includes data about the location, type of food, hours of a variety of restaurants in most metropolitan areas. More interestingly, it asks readers/eaters to post their evaluation of restaurant cost and quality (in terms of food, decor, and service). Zagat aggregates these evaluations into scores for cost, food, decor, and service for the restaurants it includes. (They also include blurbs with witty and punny remarks about the restaurants, but as an economist I'm not sure what to do with these.)
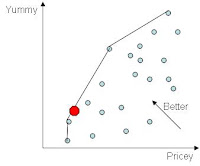
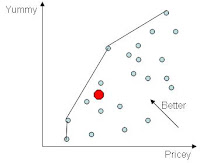
So given all this data, how do you pick a restaurant? You want to find one that is "good" but also a "good deal." This restricts you to restaurants on the price-quality frontier, but how do you identify these? Below, please see instructions for doing this. I haven't done it because:
a) Step 1 below would take a fair bit of effort;
b) I couldn't get a good publication out of it; and,
c) Without Zagat permission (which I don't have) I suspect that it's not legal to use their data.
I should say at the outset that this idea is not unique to me. This is what any decent economist would tell you to do if they thought about it. In fact, I think this is pretty much what Orley Ashenfelter does to choose wines and what was done in this paper by Olivier Gergaudy, Linett Montano Guzmanz, and Vincenzo Verardi to pick French restaurants (which was written about in a July 13th, 2006 New York Times article by fellow foodie-economist-blogger Tyler Cowen). I suspect other researchers have done this as well. (If you are an economist or statistician who has written a paper which does this or something like it, please let me know and I'll add a link to it here.)
Step 1: Enter Zagat data. Put it in a spreadsheet, with each restaurant in its own row. Columns would have "Restaurant Name", Cost, Food, Decor, Service, Neighborhood, City, Cuisine, and perhaps some of the other attibrutes (open late, etc.) Zagat includes. Convert this data into the applied statistical software of your choice, in my case STATA.
Step 2: Generate dummy variables for location (either city or neighborhood) and cuisine. There is one of these for each location or cuisine, and they take on a value of 1 if the restaurant is in that location (or of that cuisine) and zero otherwise. You will want to lump together any categories that are similar but with few observations. (I'd put Lao food in with the Thai category unless there are a lot more Lao restaurants on Zagat than I expect. In Baltimore, you would want to lump together nearby or similar neighborhoods into groups. You want at least 20 values of "1" for each dummy variable, but given the large number of cities in the data this shouldn't be too hard.) You may also want to create a polynomial function of food, decor, and service, by creating variables like food², decor², or even food×decor.
Step 3: Run an OLS (ordinary least squares) regression to predict "cost" with food, service, decor (and perhaps the squared and cubed and cross-multiplied versions of these variables), location dummies, and cuisine dummies. Collect the "residuals" from this regression. Multiply them by negative one and call them "value".
Step 4: Choose a restaurant with a very high (highly positive) value (or equivalently a strongly negative residual). This restaurant is cheap for how good it is, what kind of food it is, and where it is located. You can then look for the restaurant in your preferred price range, neighborhood, or cuisine type with the best value.
(Optional Step 5: Make your own personal value measure to your taste by calculating your own residuals. If you particularly value decor but don't care about food, you can make your own residuals by using different coefficients on those variables than the one given by the regression. Don't do this unless you know enough statistics/econometrics that you can scale your adjustments properly or this will go badly.)
I'm surprised that Zagat doesn't put up a list of the restaurants in each city with the best value by this criteria. They do have a list of good deals, but they obviously use another criteria, as their "good deal" picks are invariably cheap and come from cuisines (e.g., coffee shop, pizza) where all the prices are low. The cuisine dummy variables I discussed fix this problem.
(N.B. 1: Tim and Nina Zagat, call me. We can improve your lists of preferred restaurants. Or you could add a list of "economist picks" online or have several statisticians/economists each of us post our preferred lists. It would make all the great data in your guides more useful and actionable. You could add in a tool to come up with customized picks based on an idiot-proof user interface that let's people do Step 5. They would enter in the relative importance they place on various attributes and would get individual-specific ratings.)
(N.B. 2: This would make a good undergraduate senior thesis, particularly if you set up Step 5.)